Multi-Headed Attention
Introduction
Multi-headed attention is a key component of modern neural networks, particularly in the Transformer architecture. It allows the model to focus on different parts of the input simultaneously, capturing a variety of relationships and patterns. Let’s explore how this mechanism works.
Self Attention Problem
Although using self attention brings us a lot of advantages, there are some problems that we may consider.
Let’s talk a bit about Convolution. 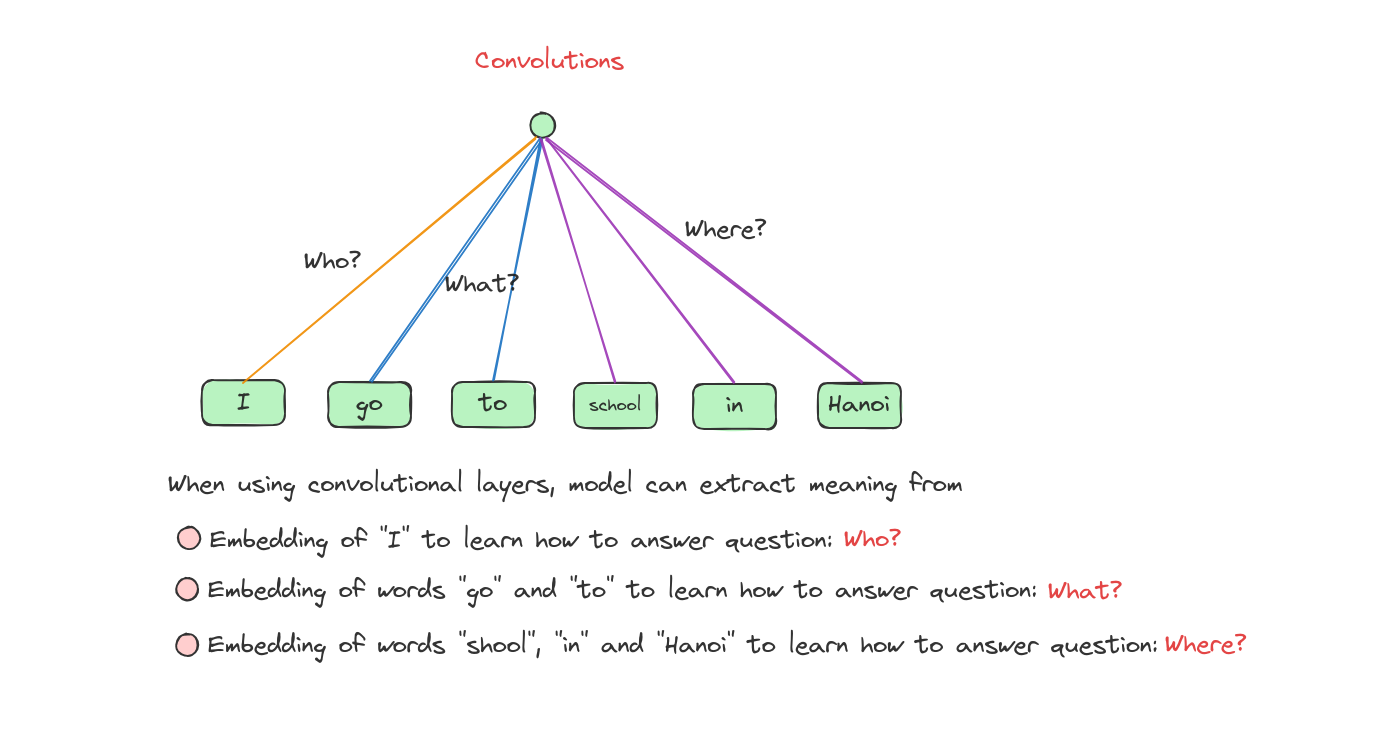
Limitations of self attention: 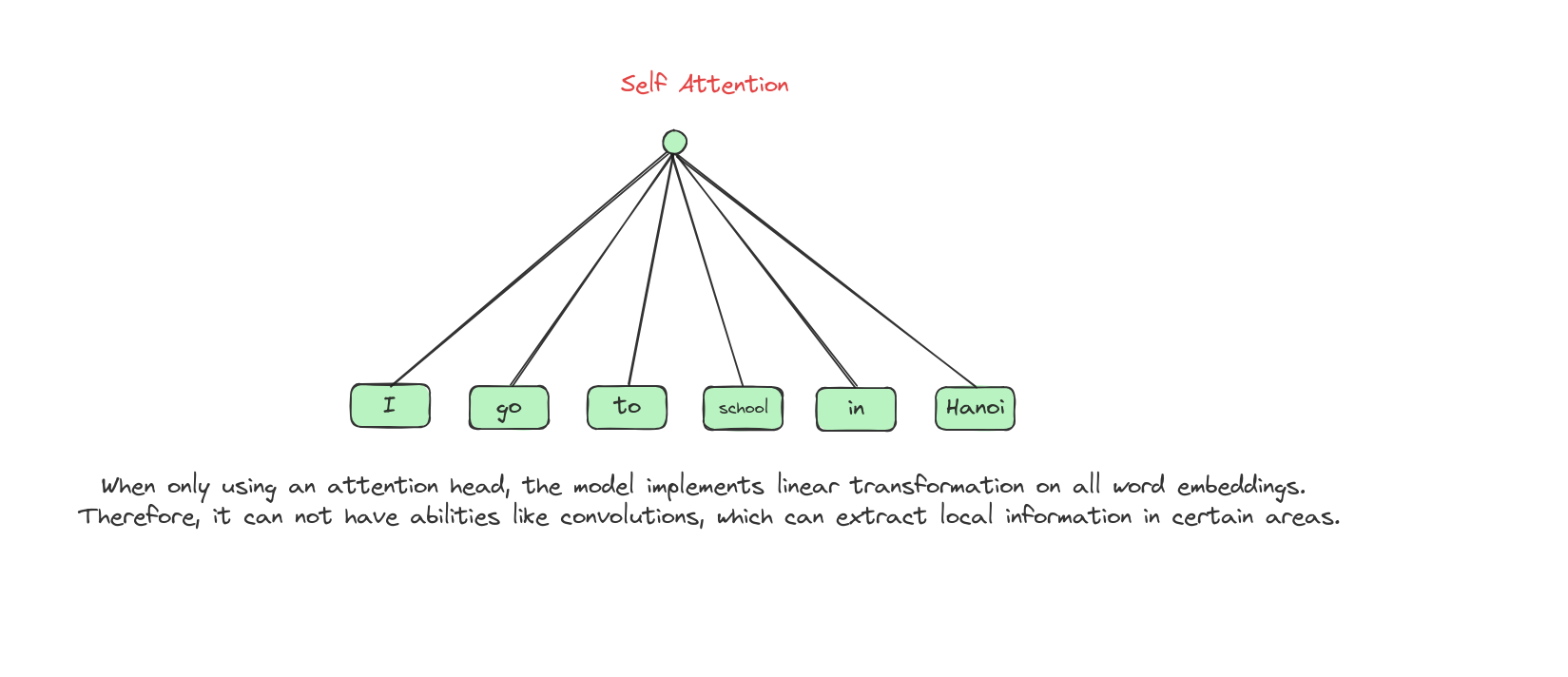
Therefore, we need to use many attention heads to simulate the abilities of using convolutions. 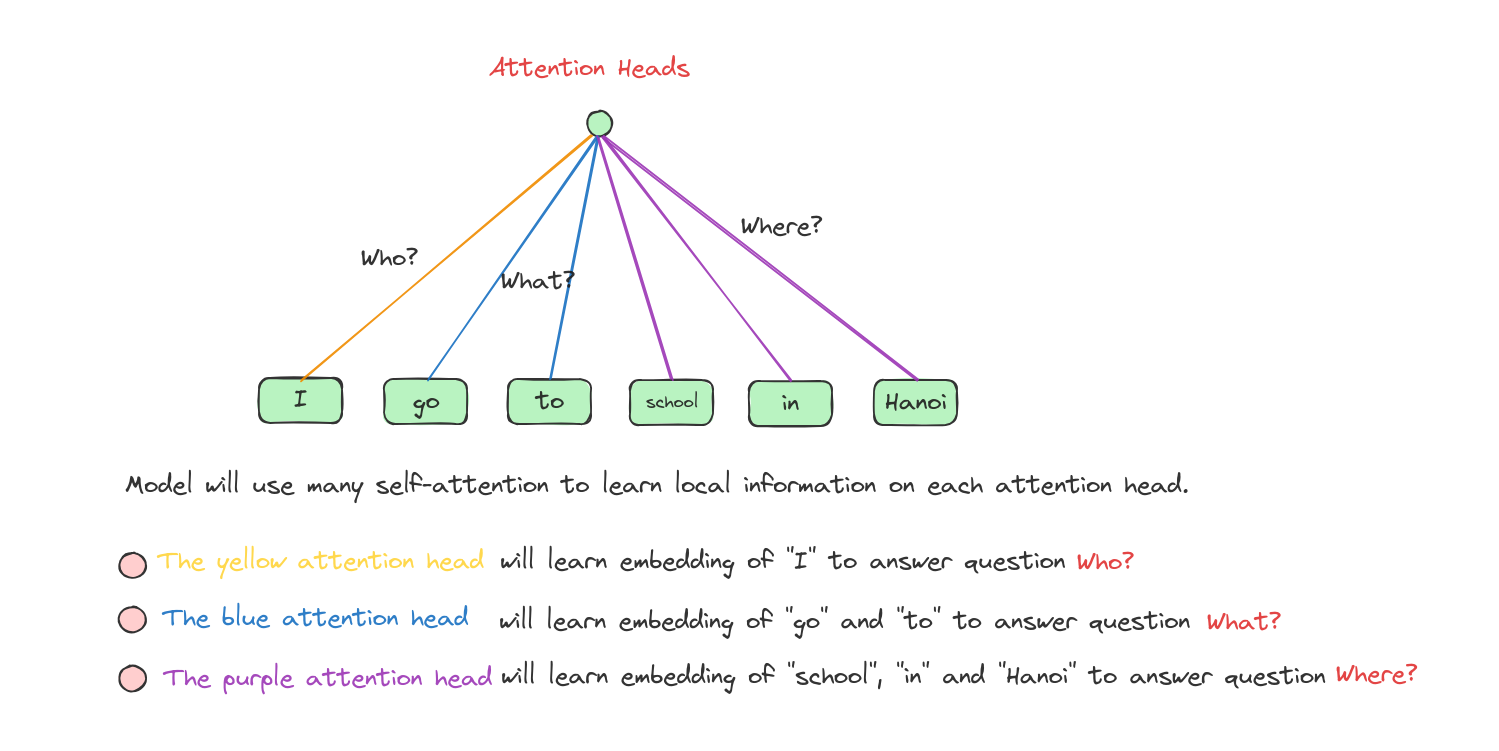
Multi-Headed Attention
Many attention heads expands the model’s ability to focus on different positions. 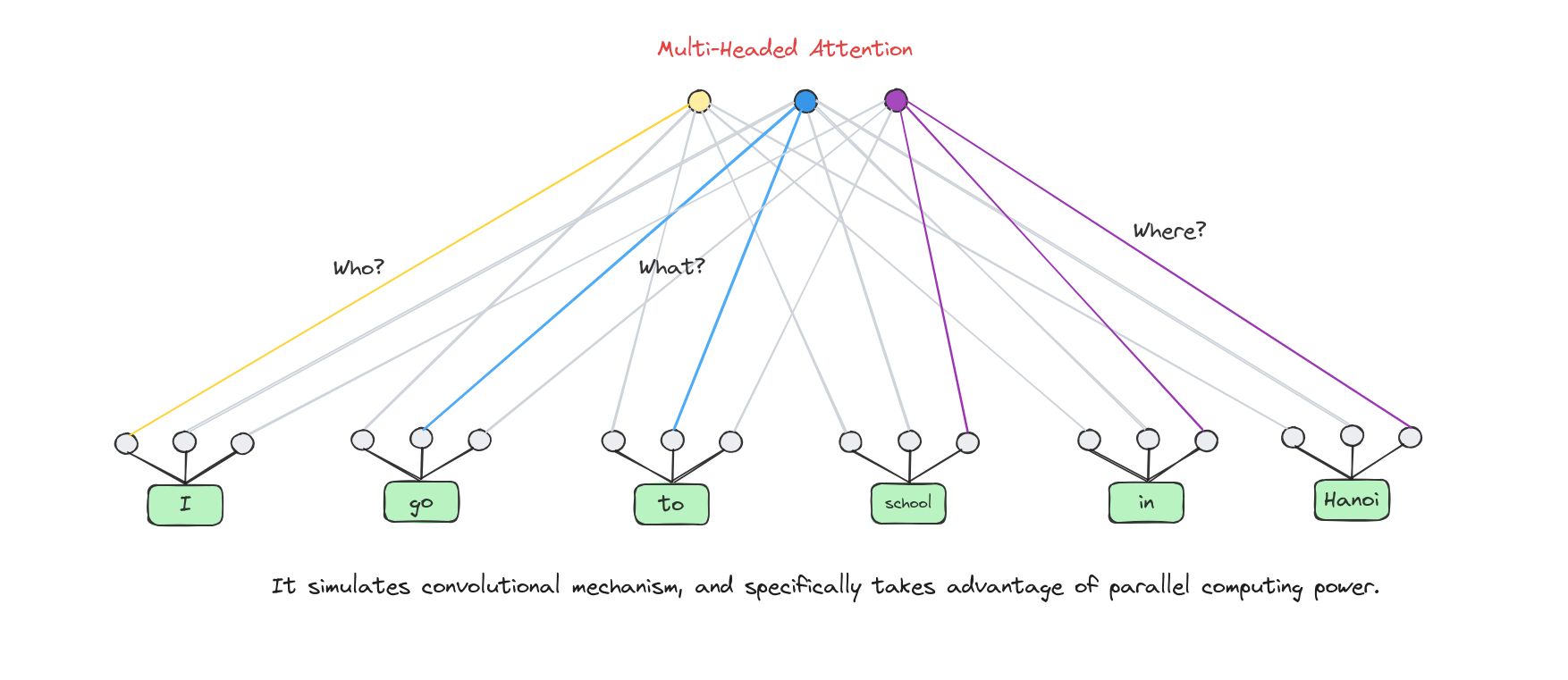
From original word embeddings, we divide them into 3 parts in case we use 3 attention heads.
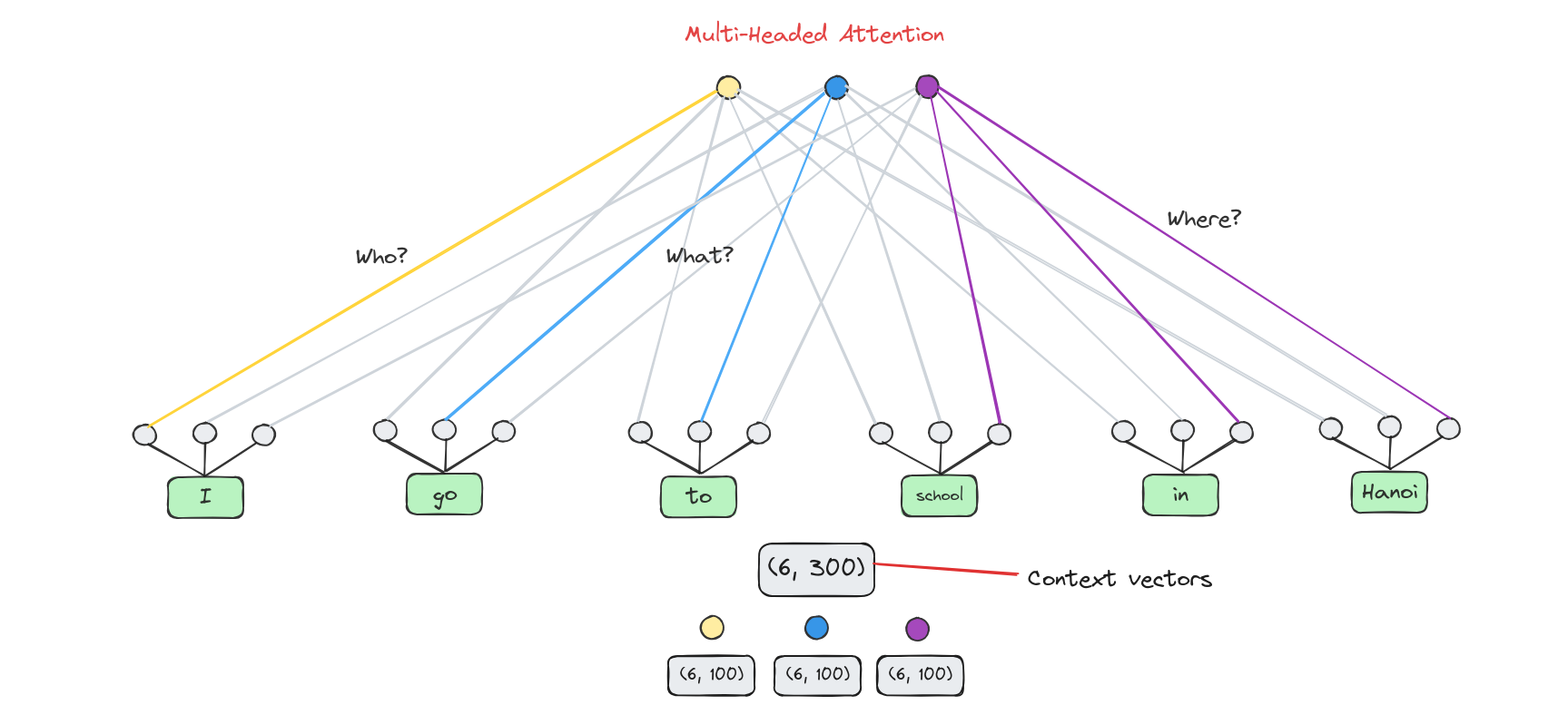
Note: The number of heads must be a divisor of embedding’s length
Multi-Headed attention architecture
Multi-Headed attention has the core component is self attention. Besides, it has some linear layers to map to desiable dimentions. 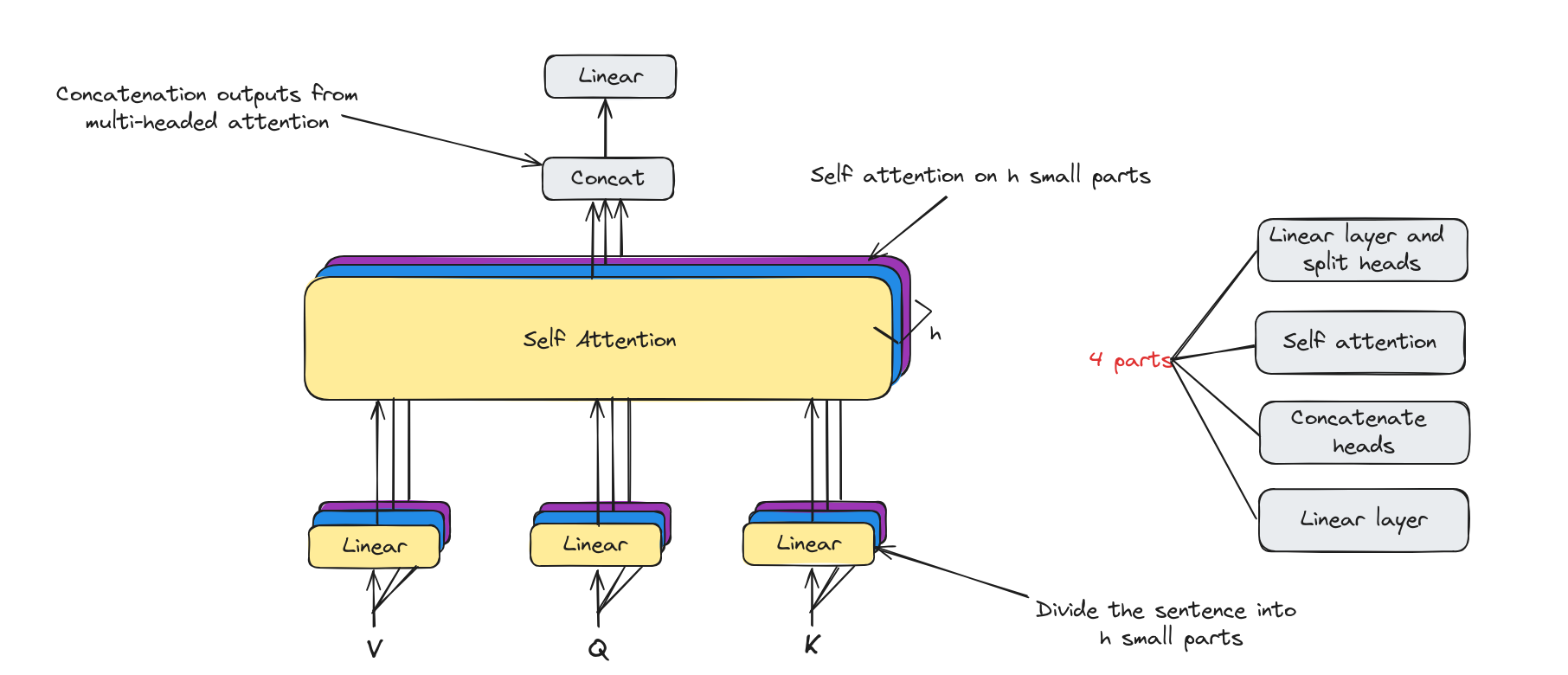
Now, we will deep dive into each components.
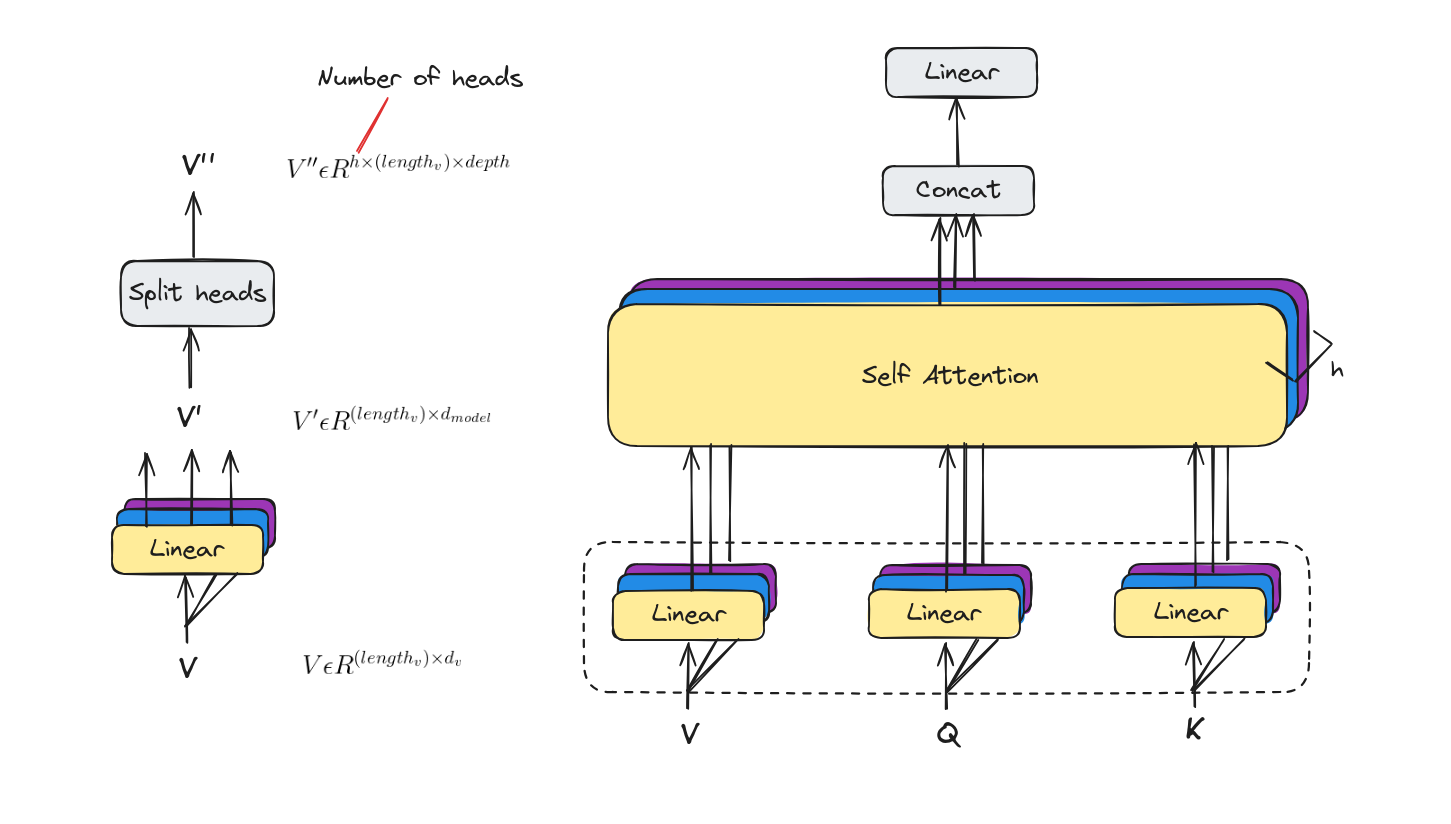
Linear layers and split into heads
With multi-headed attention we have not only one, but multiple sets of Query/Key/Value weight matrices. Each of these sets is randomly initialized.
Self attention
Calculate attention using the resulting Query/Key/Value matrices on each head.
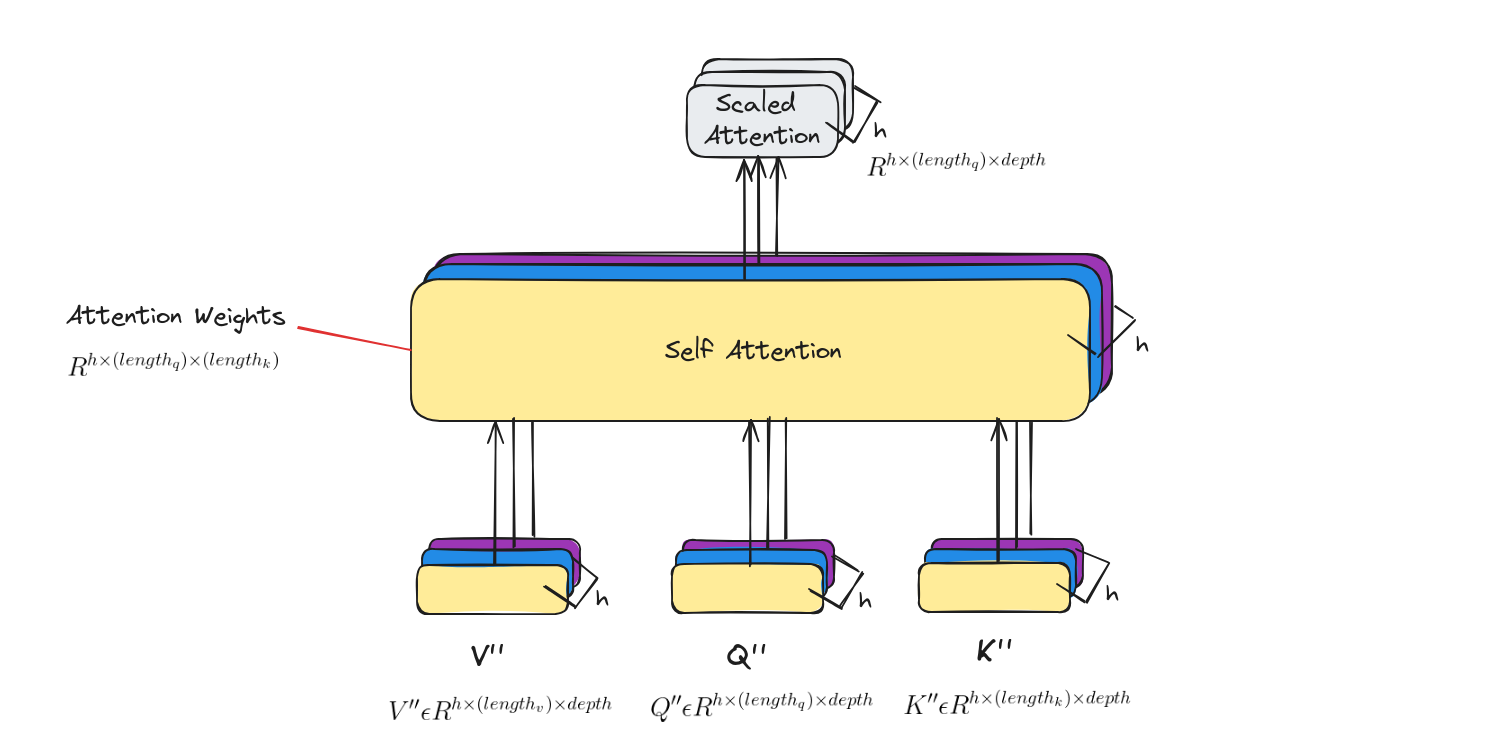
Concat and Final Linear Layer

Conclusion
In summary, the lesson on multi-headed attention demonstrated how this powerful mechanism allows neural networks to focus on multiple parts of the input simultaneously.
By capturing diverse patterns and relationships, multi-headed attention significantly enhances tasks like language translation and text generation.
References
- J. Alammar, “The Illustrated Transformer,” jalammar.github.io, Jun. 27, 2018. https://jalammar.github.io/illustrated-transformer/