Word Embedding
Giới thiệu
Word Embedding là một kỹ thuật trong NLP để biểu diễn các từ trong không gian vector liên tục. Khác với các cách biểu diễn truyền thống, word embedding giúp mô hình nắm bắt được mối quan hệ ngữ nghĩa giữa các từ, cho phép hiểu được ngữ cảnh và ý nghĩa.
Xử lý ngôn ngữ tự nhiên
NLP là một nhánh của Trí tuệ nhân tạo . Nó giúp máy tính có khả năng đọc, hiểu và suy luận ngôn ngữ của con người.
Sự phát triển của NLP
Ngày nay, NLP đã đạt được nhiều cột mốc đáng nhớ. Đầu tiên là sự xuất hiện của Word2Vec, cho phép biểu diễn một câu hoặc từ bằng một con số xác định. Để cải thiện biểu diễn này, attention mechanism ra đời, là tiền đề cho mô hình transformer—bước đột phá trong nghiên cứu AI và là nền tảng cho nhiều mô hình nổi bật như GPT-4, Gemini, LLama2.
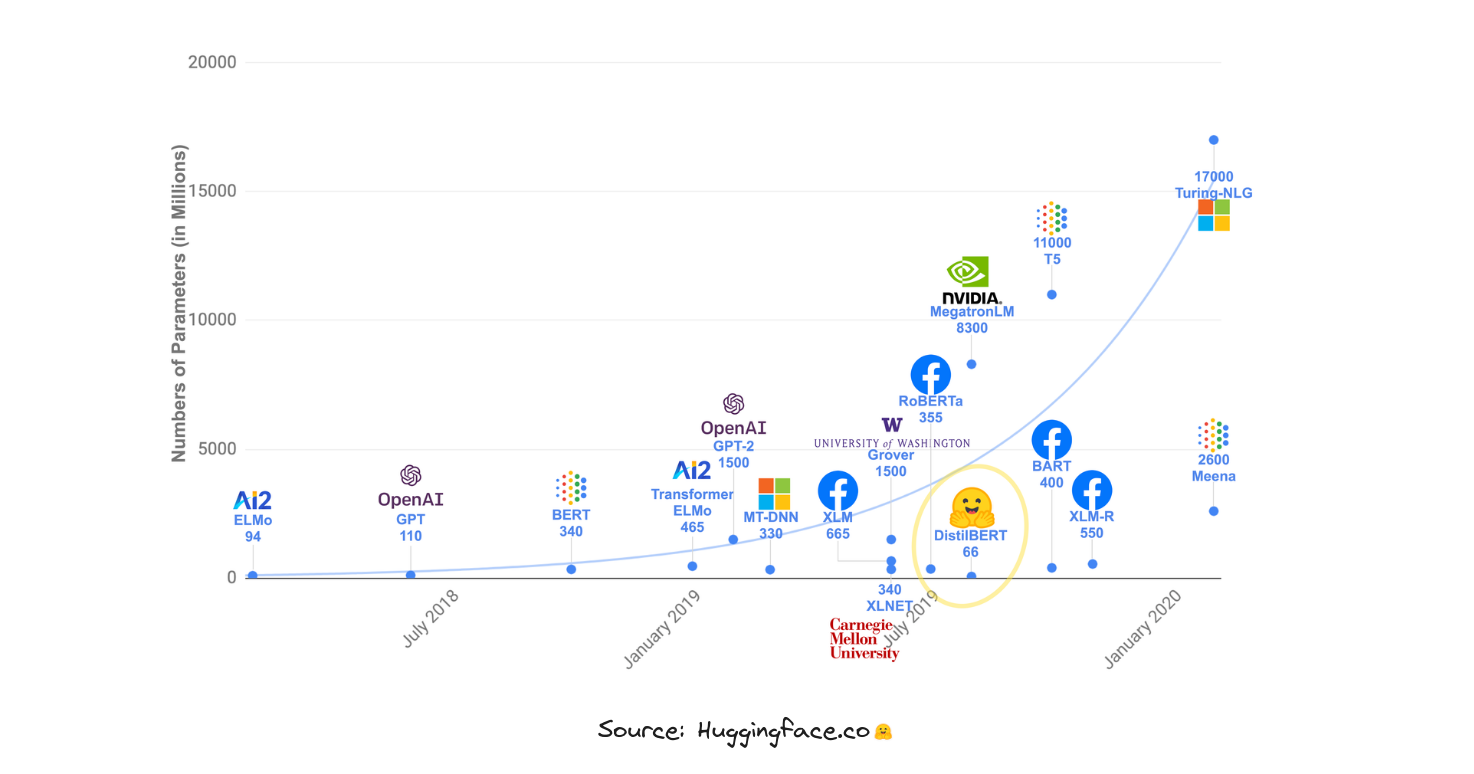
Tuy nhiên, tất cả các mô hình này sẽ không hoạt động hiệu quả nếu không có một cách biểu diễn ngôn ngữ mạnh mẽ gọi là Word Embedding. 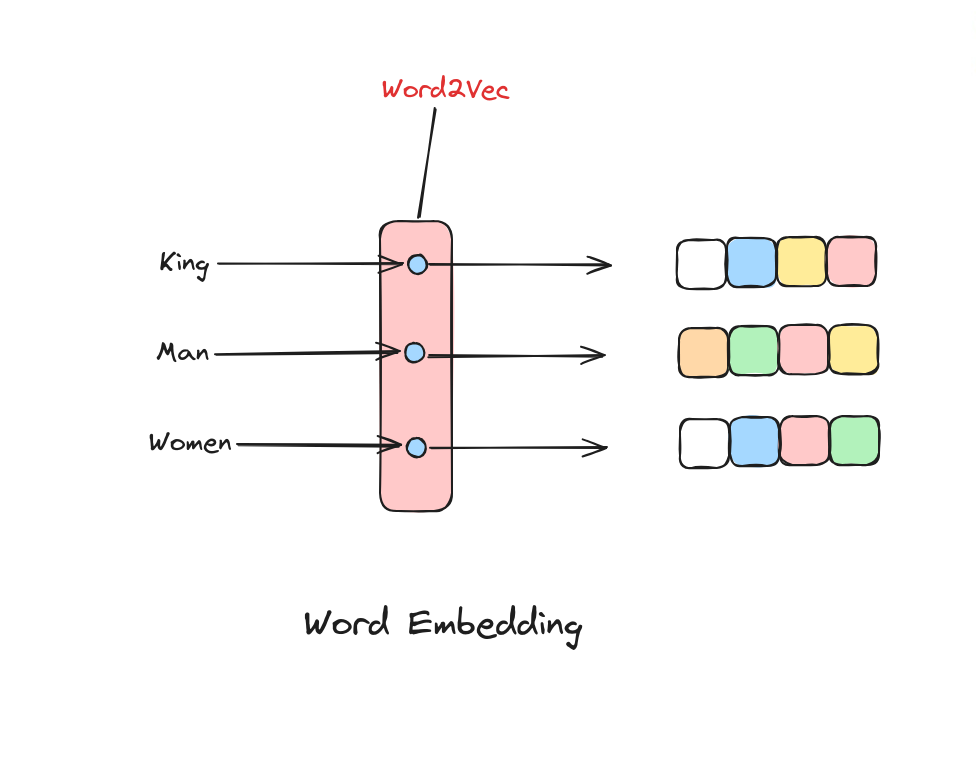
Thách thức của Word Embedding
Ba khó khăn chính khi xây dựng hệ thống word embedding là:
- Đa nghĩa (Ambiguous).
- Thành ngữ (Idioms).
- Ý nghĩa phụ thuộc vào ngữ cảnh (Meaning depends on context).
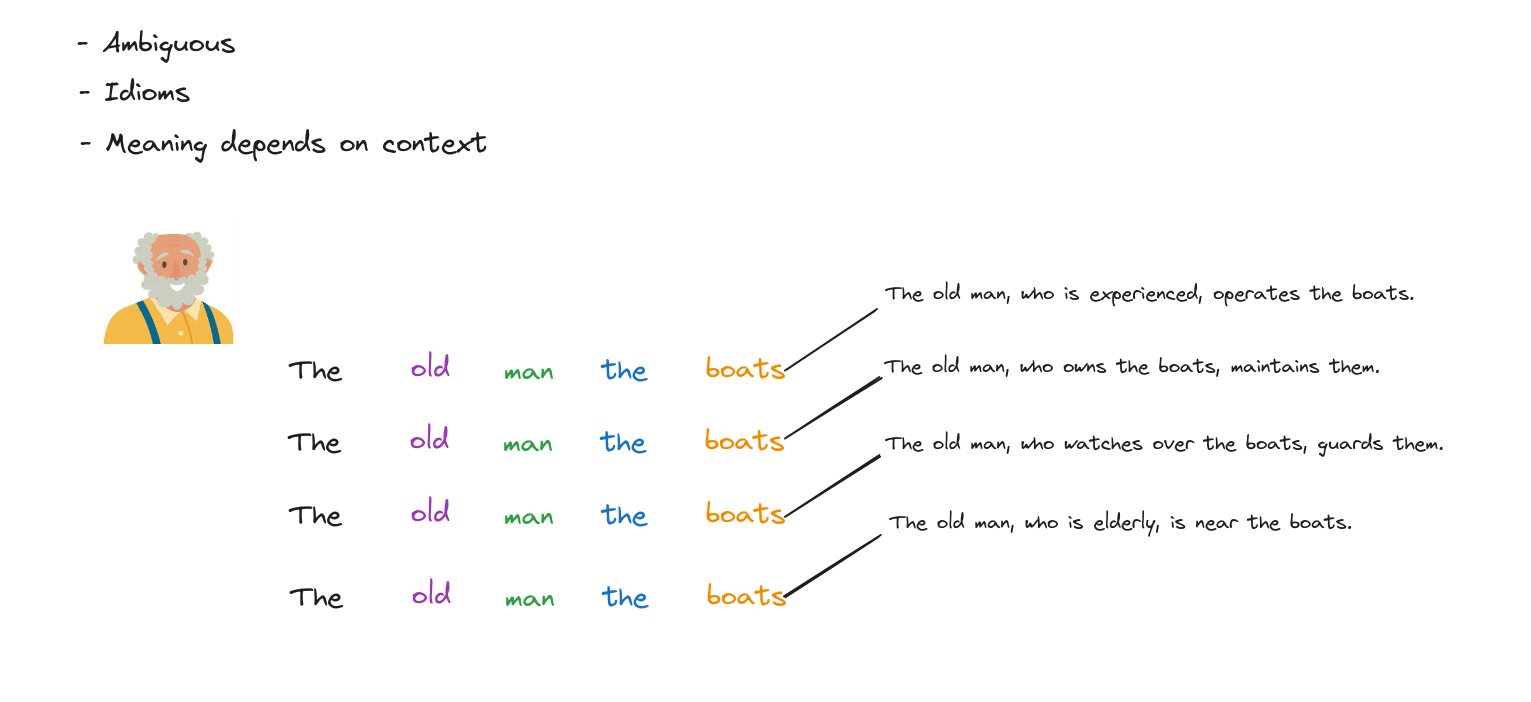
Ví dụ, với câu “The old man the boats”, ta không thể biết nghĩa thực sự nếu không dựa vào các câu xung quanh, nên embedding phải khác nhau tùy trường hợp. Thành ngữ cũng là trường hợp khó biểu diễn.
Tokenizer
Tokenizer là quá trình chia câu, cụm từ, đoạn văn hoặc toàn bộ tài liệu thành các đơn vị nhỏ hơn, có thể là từ hoặc ký tự. Mỗi đơn vị này gọi là một token.
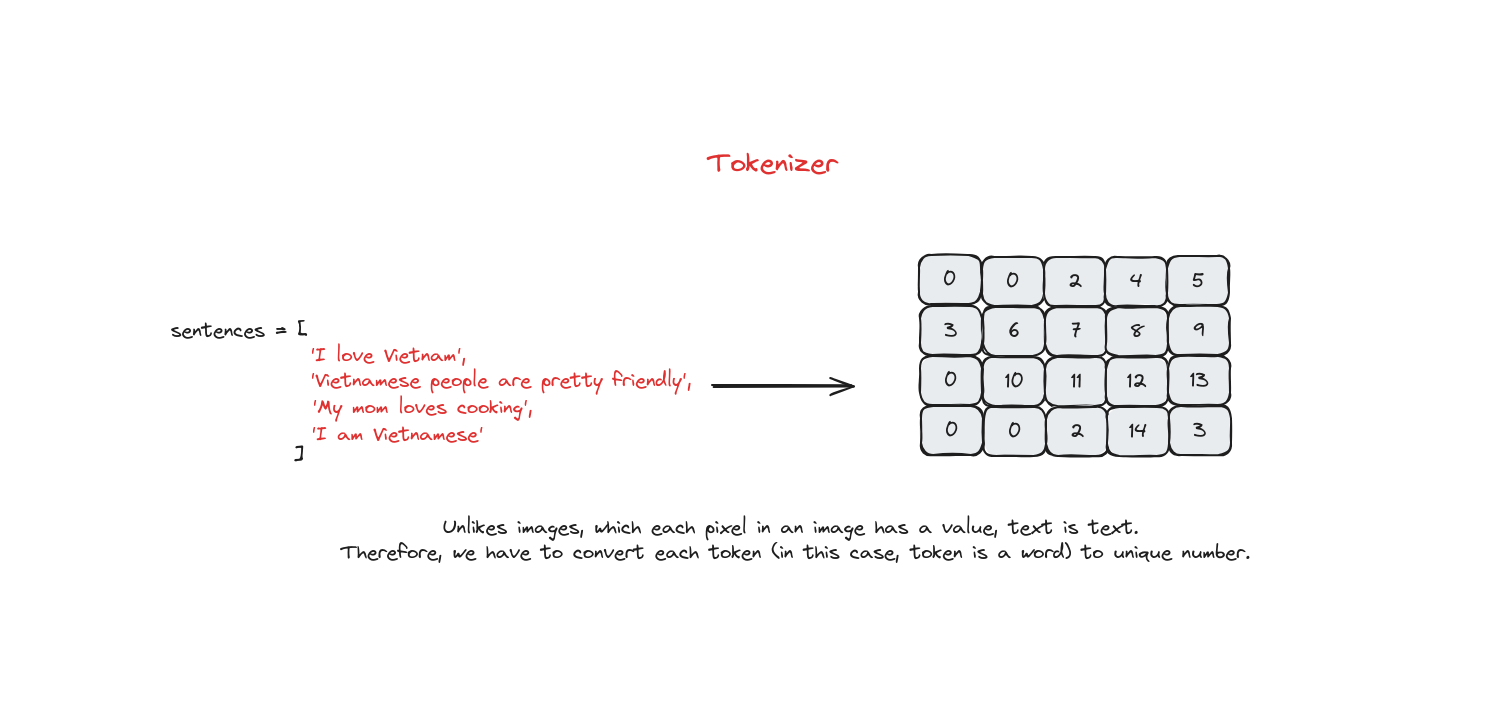
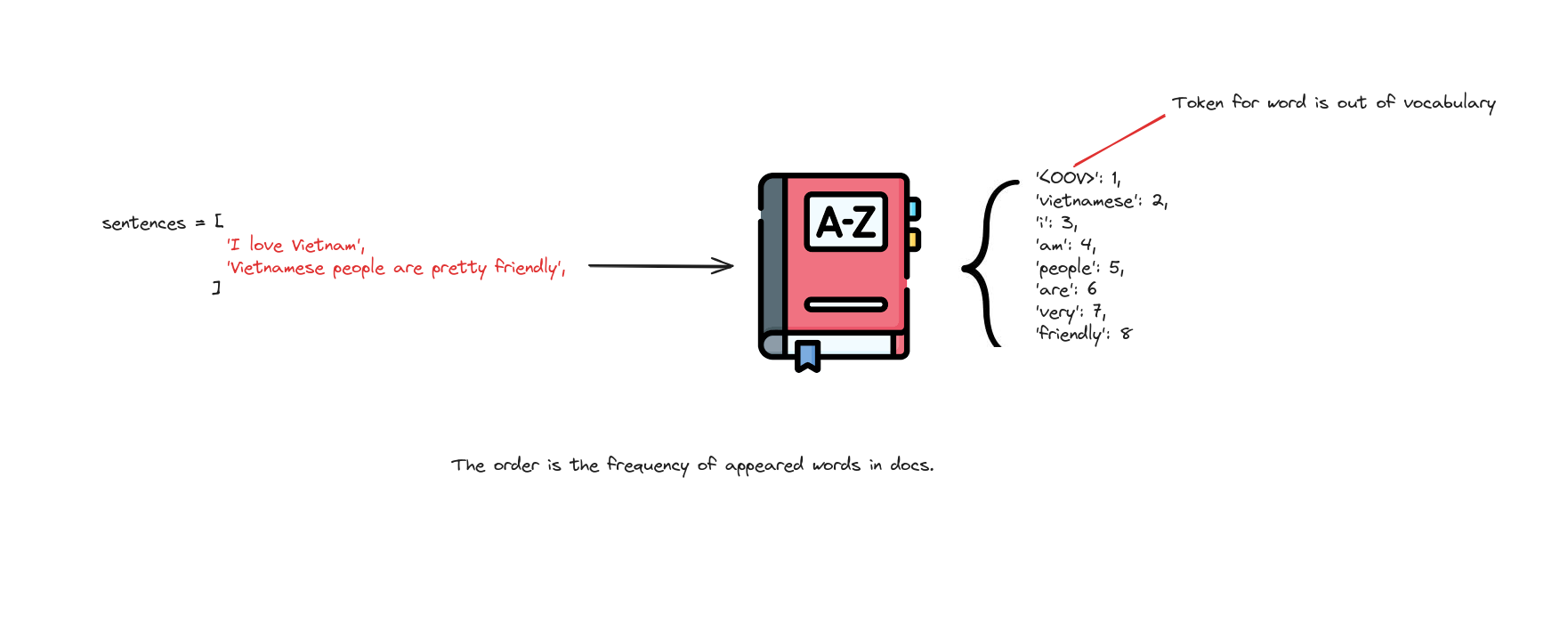
Gần đây, có nhiều kỹ thuật tokenizer tiên tiến được sử dụng trong các mô hình SOTA như Byte-Pair Encoding, WordPiece, SentencePiece.
Ngữ nghĩa từ vựng
Lexical semantics là một nhánh của ngôn ngữ học nghiên cứu về ý nghĩa và mối quan hệ giữa các từ. Nó xem xét cách các từ được cấu trúc, diễn giải và liên kết với nhau trong một ngôn ngữ.
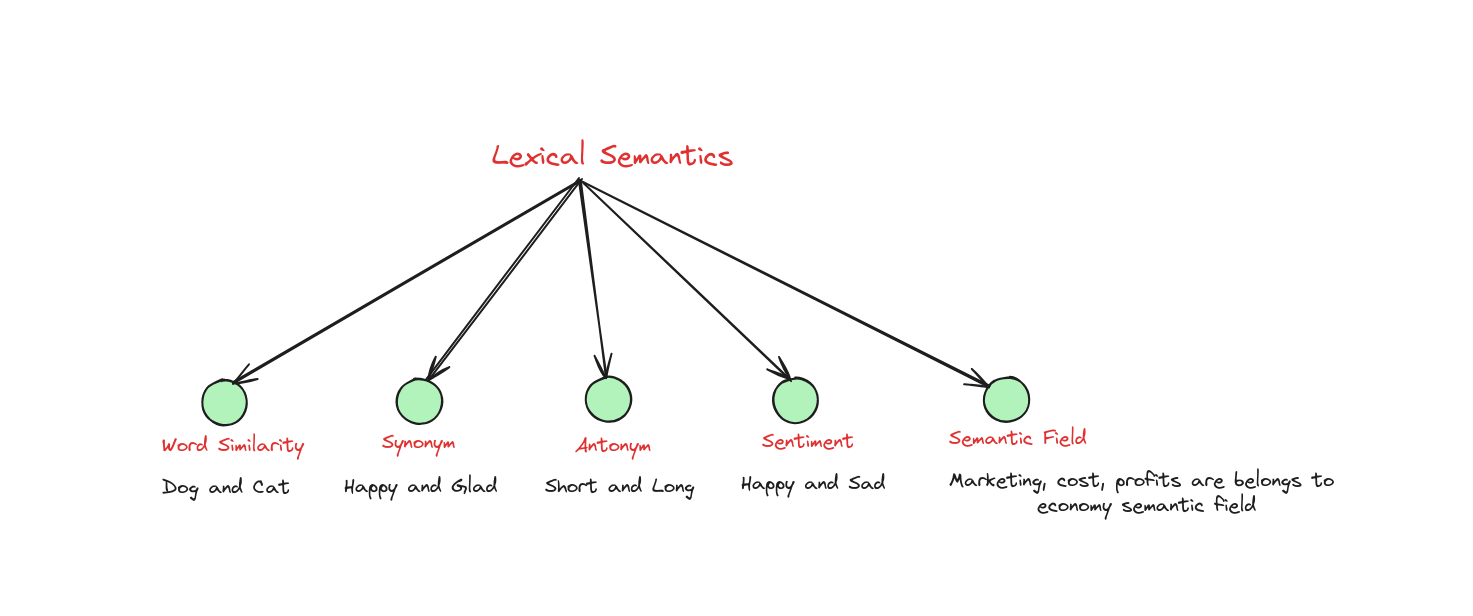
Ví dụ về Word Similarity: hai từ “dog” và “cat” không phải là từ đồng nghĩa, nhưng chúng khá gần nhau về mặt ý nghĩa. Cách ta nói “dog is very lovely” và “cat is very lovely” rất giống nhau. Việc xem xét ngữ nghĩa từ vựng trên cặp từ giúp xây dựng Word Embedding sau này.
Semantic vector
Semantic vector là cách biểu diễn một từ trong không gian ngữ nghĩa nhiều chiều, được xây dựng dựa trên mối quan hệ giữa từ đó và các từ xung quanh.
Hai từ gần nhau trong không gian ngữ nghĩa sẽ có ý nghĩa tương tự nhau.
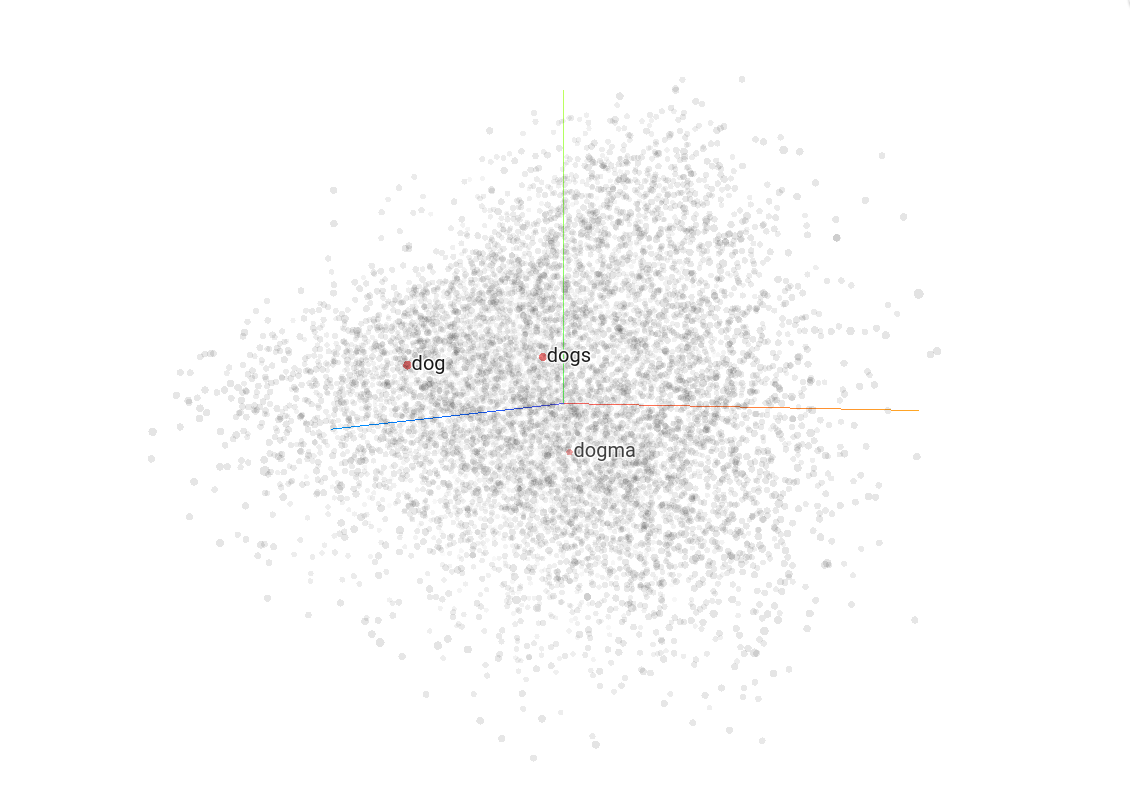
Lưu ý: Để thử nghiệm với semantic vector,truy cập Tensorflow Projector.
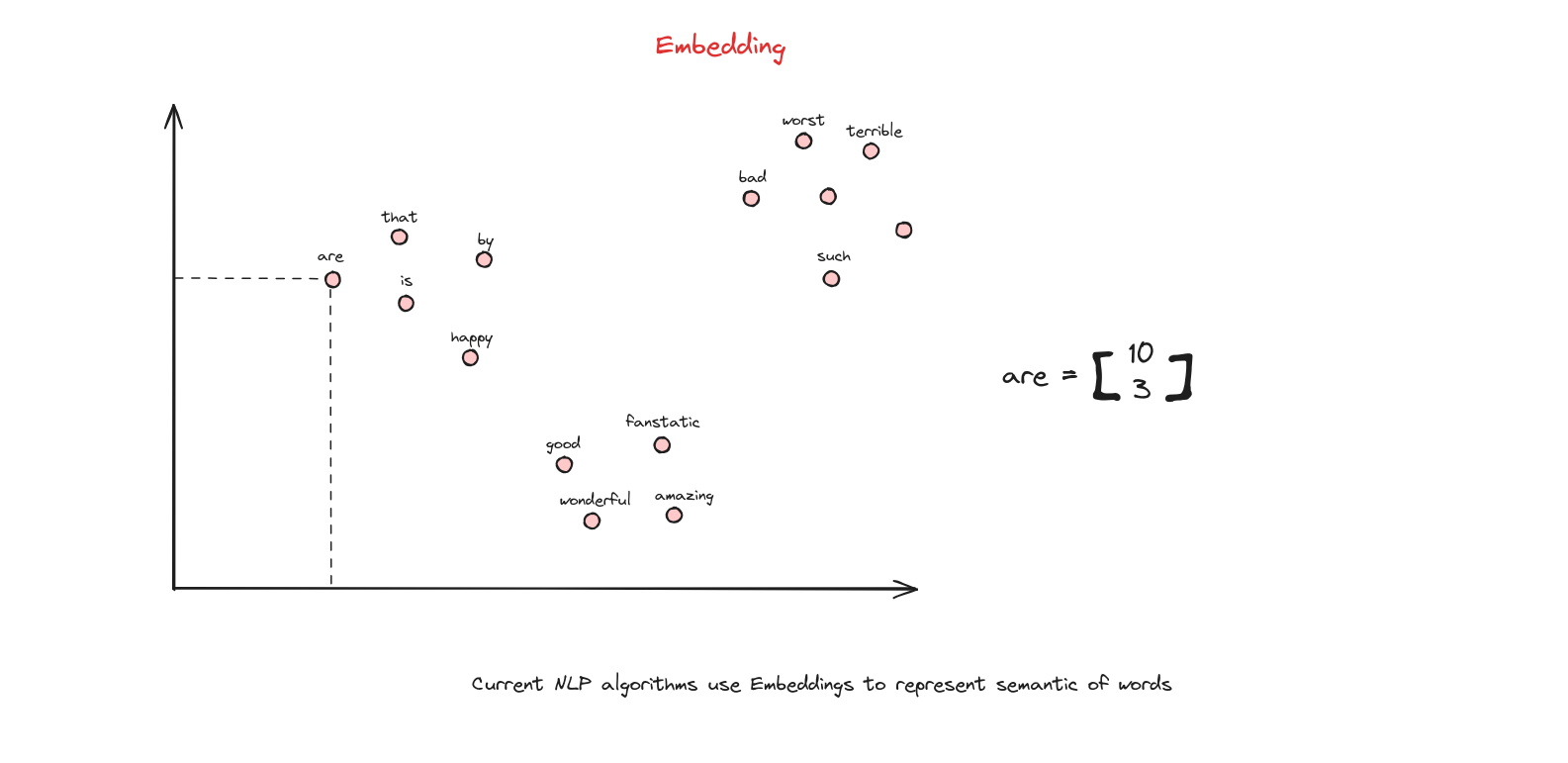
Embedding
Embedding là tập hợp các semantic vector. Từ “semantic” ở đây nhấn mạnh rằng các vector này không phải ngẫu nhiên mà được thiết kế để nắm bắt và biểu diễn ý nghĩa, mối quan hệ giữa các từ trong ngôn ngữ, giúp các tác vụ NLP hiệu quả và tinh tế hơn.
Các loại Embedding
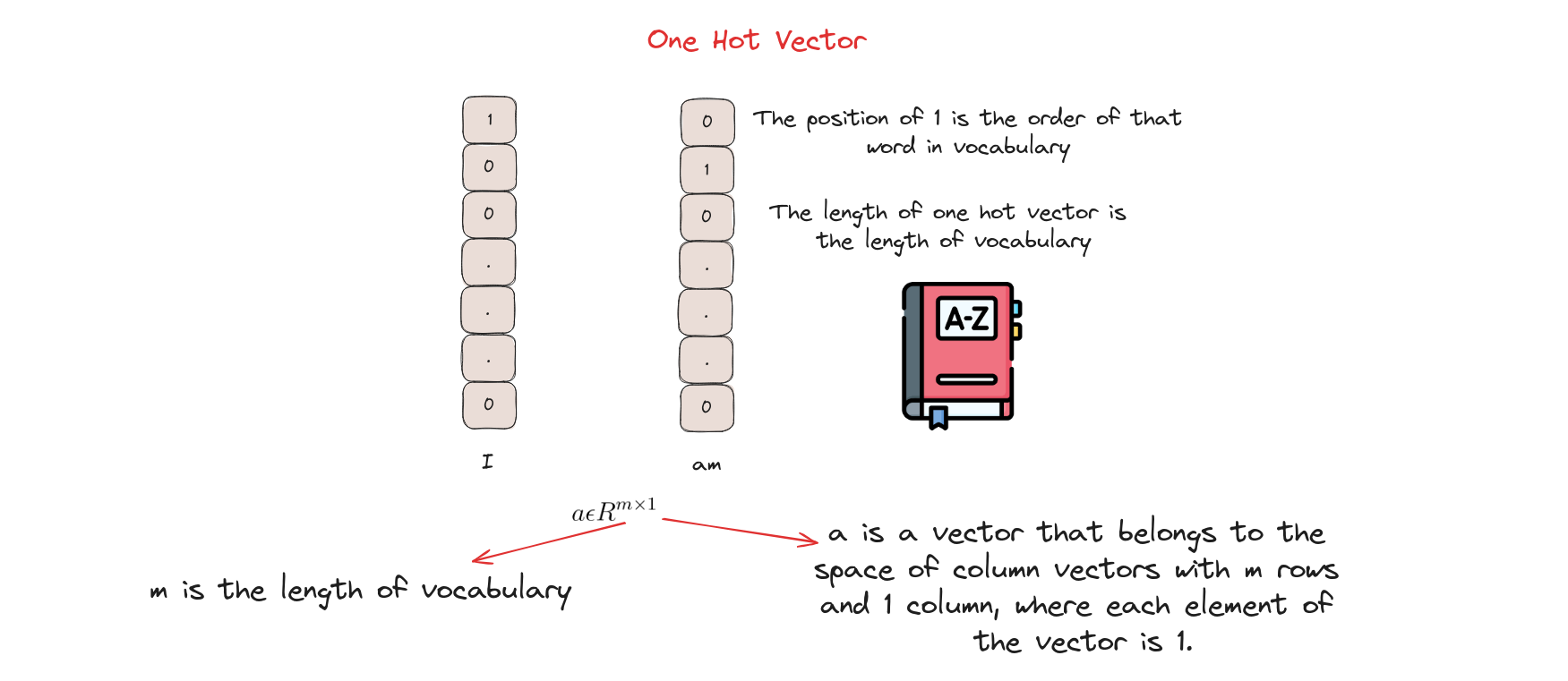
One Hot Vector
One Hot Encoding là biến mỗi token thành một vector nhị phân. Đầu tiên, mỗi token được gán một giá trị số nguyên. Sau đó, số nguyên này được biểu diễn thành vector nhị phân, tất cả các giá trị là 0 trừ vị trí của số nguyên đó là 1.
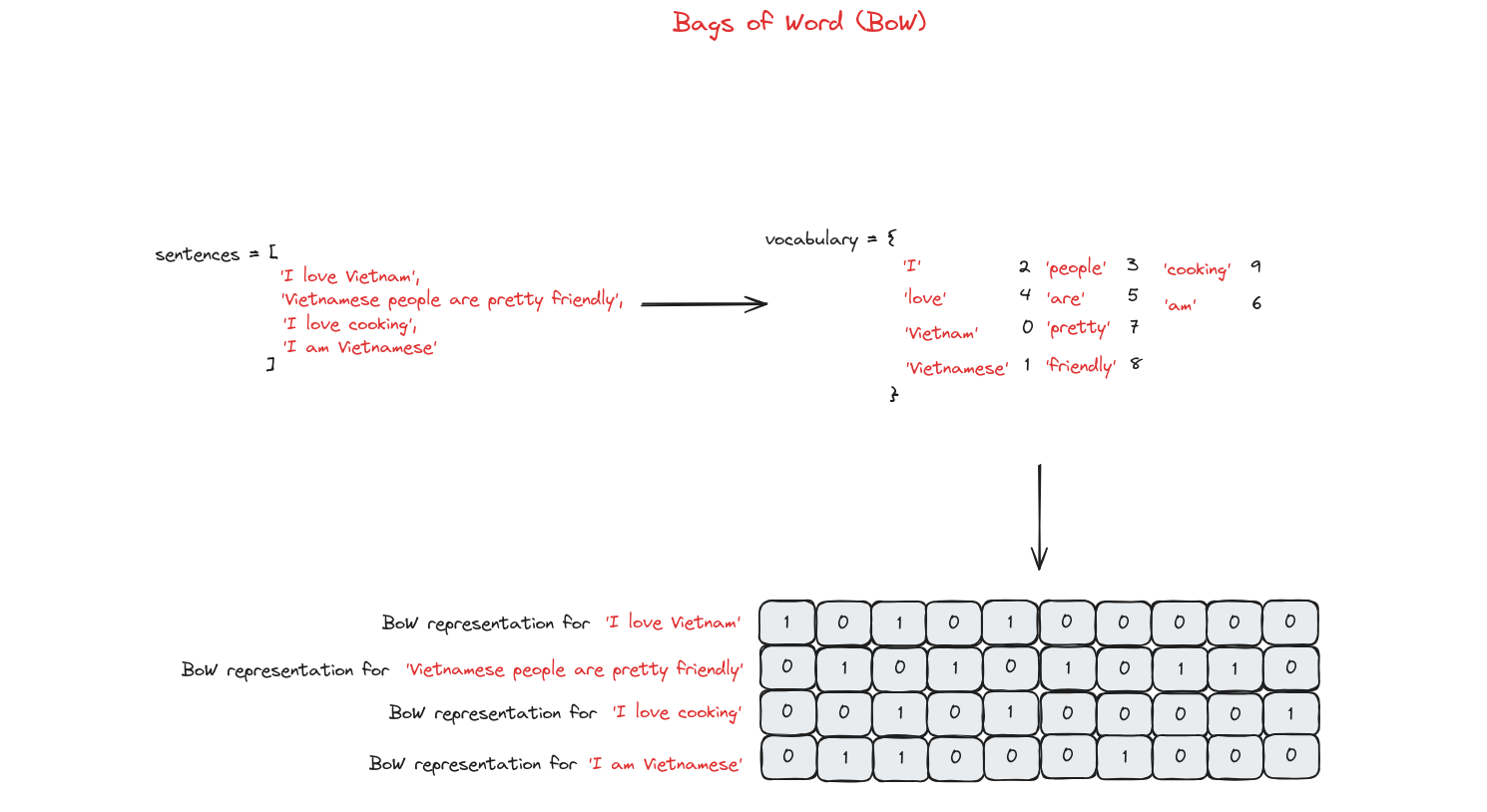
Bag of Words (BoW)
Bag of Words chỉ xem xét từ nào xuất hiện trong tài liệu và tần suất xuất hiện, không quan tâm đến ngữ pháp hay thứ tự từ.
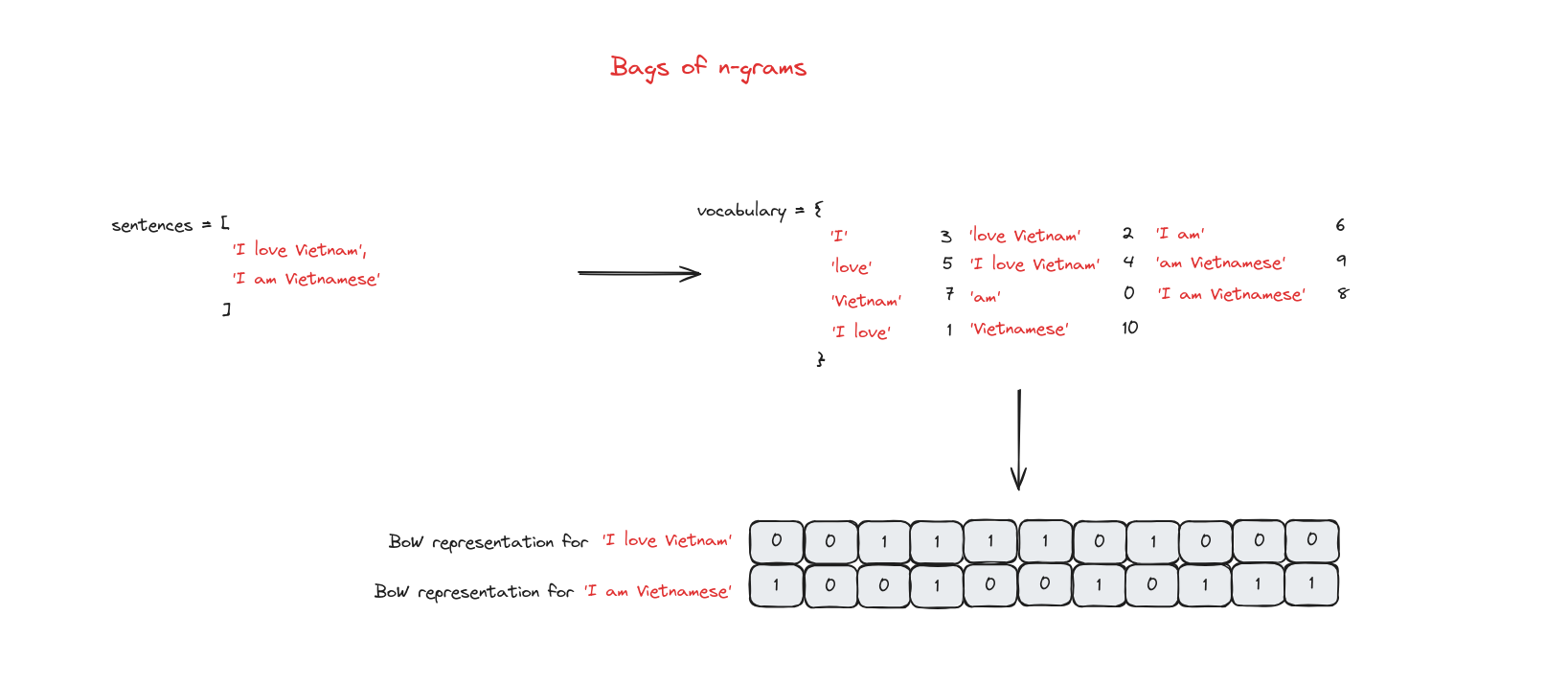
Bag of n-grams
Trong Bag of Words, cụm từ và thứ tự từ không được xét đến. Bag of n-grams khắc phục điều này bằng cách chia văn bản thành các nhóm gồm n từ liên tiếp.
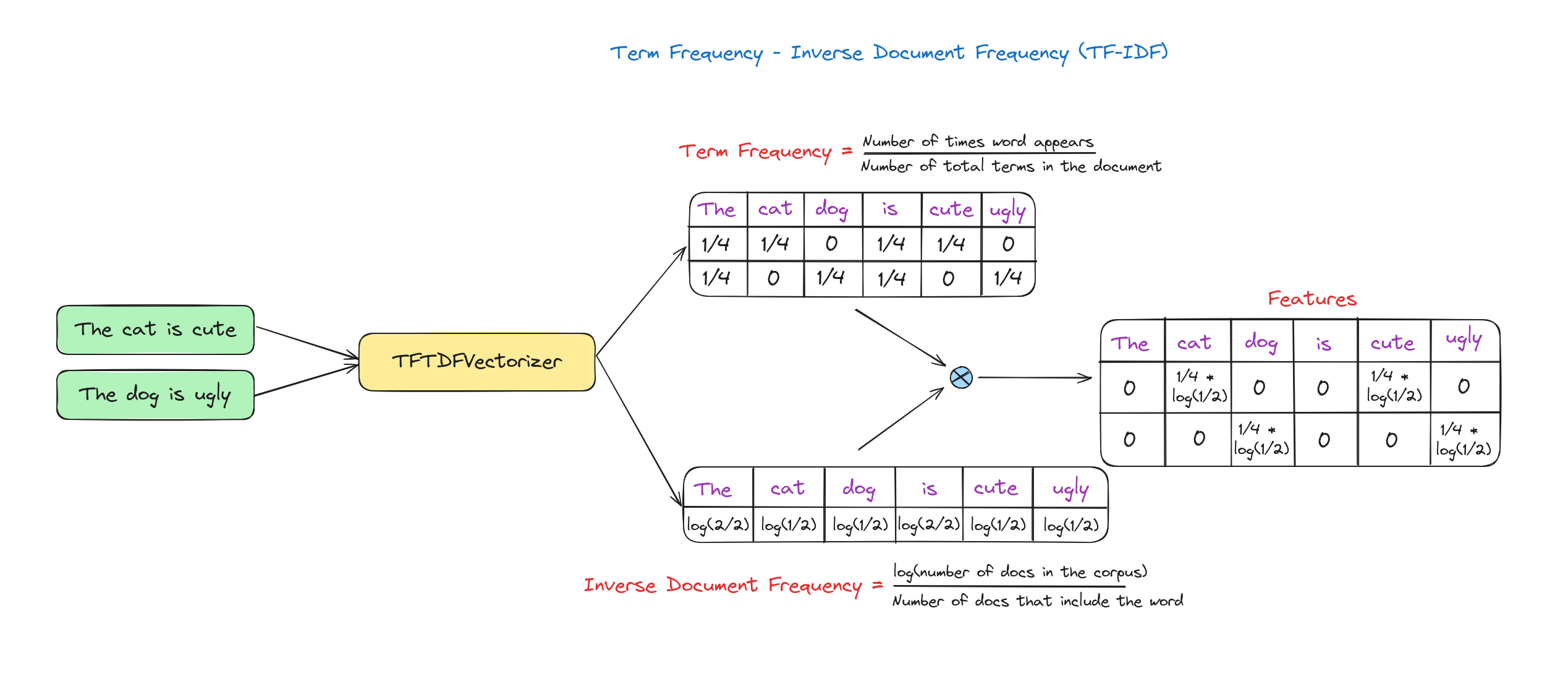
TF-IDF
Ở các phương pháp trên, mọi từ đều có trọng số như nhau. Tuy nhiên, TF-IDF đánh giá tầm quan trọng của một từ trong toàn bộ tập dữ liệu (corpus).
Term Frequency (TF): Đo tần suất xuất hiện của một từ trong tài liệu, tính bằng tỉ lệ số lần xuất hiện của từ đó trên tổng số từ trong tài liệu.
Inverse Document Frequency (IDF): Đo tầm quan trọng của từ trên toàn bộ tập dữ liệu, giảm trọng số cho từ phổ biến và tăng trọng số cho từ hiếm.
TF-IDF Score: Là tích của TF và IDF.
Hình dưới minh họa cách tính TF-IDF.
Ví dụ dưới đây là cách triển khai TF-IDF trong Python.
import nltk
nltk.download('punkt') # Download 'punkt'
# from nltk if it's not downloaded
from sklearn.feature_extraction.text import TfidfVectorizer
sentences = ["I love Vietnam", "Vietnamese people are pretty friendly",\
"I love cooking", "I am Vietnamese"]
# TF-IDF
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(sentences)
# All words in the vocabulary.
print("vocabulary", tfidf.get_feature_names_out())
# IDF value for all words in the vocabulary
print("IDF for all words in the vocabulary :\n", tfidf.idf_)
# TFIDF representation for all documents in our corpus
print('\nTFIDF representation for "{}" is \n{}'
.format(sentences[0], tfidf_matrix[0].toarray()))
print('TFIDF representation for "{}" is \n{}'
.format(sentences[1], tfidf_matrix[1].toarray()))
print('TFIDF representation for "{}" is \n{}'
.format(sentences[2],tfidf_matrix[2].toarray()))
# TFIDF representation for a new text
matrix = tfidf.transform(["learning dsa from geeksforgeeks"])
print("\nTFIDF representation for 'learning dsa from geeksforgeeks' is\n",
matrix.toarray())
Kết quả:
vocabulary ['am' 'are' 'cooking' 'friendly' 'love' 'people' 'pretty' 'vietnam'
'vietnamese']
IDF for all words in the vocabulary :
[1.91629073 1.91629073 1.91629073 1.91629073 1.51082562 1.91629073
1.91629073 1.91629073 1.51082562]
TFIDF representation for "I love Vietnam" is
[[0. 0. 0. 0. 0.6191303 0.
0. 0.78528828 0. ]]
TFIDF representation for "Vietnamese people are pretty friendly" is
[[0. 0.46516193 0. 0.46516193 0. 0.46516193
0.46516193 0. 0.36673901]]
TFIDF representation for "I love cooking" is
[[0. 0. 0.78528828 0. 0.6191303 0.
0. 0. 0. ]]
TFIDF representation for 'I love vietnamese people' is
[[0. 0. 0. 0. 0.52640543 0.66767854
0. 0. 0.52640543]]
Trong phạm vi bài này sẽ tập trung vào Word2Vec, một kỹ thuật Word Embedding được sử dụng rộng rãi trong các mô hình hiện đại.
Word Embeddings
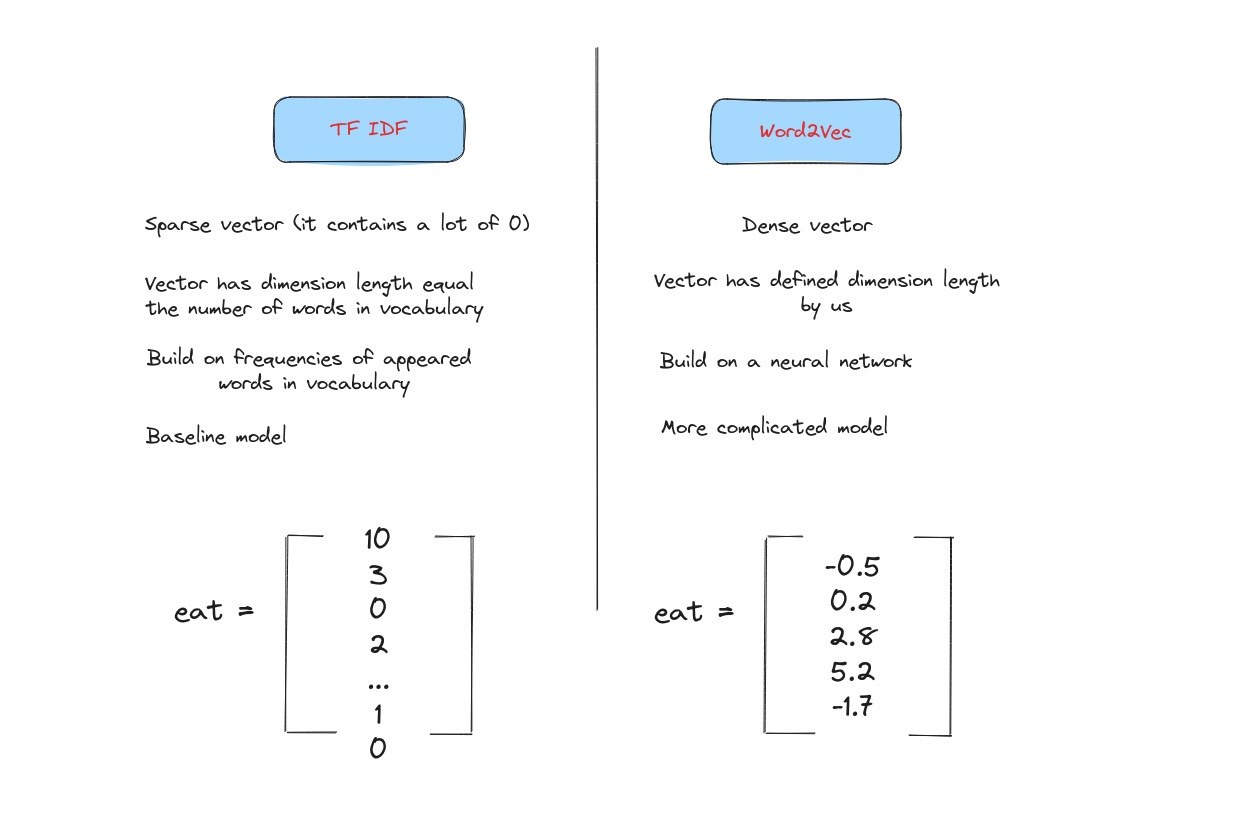
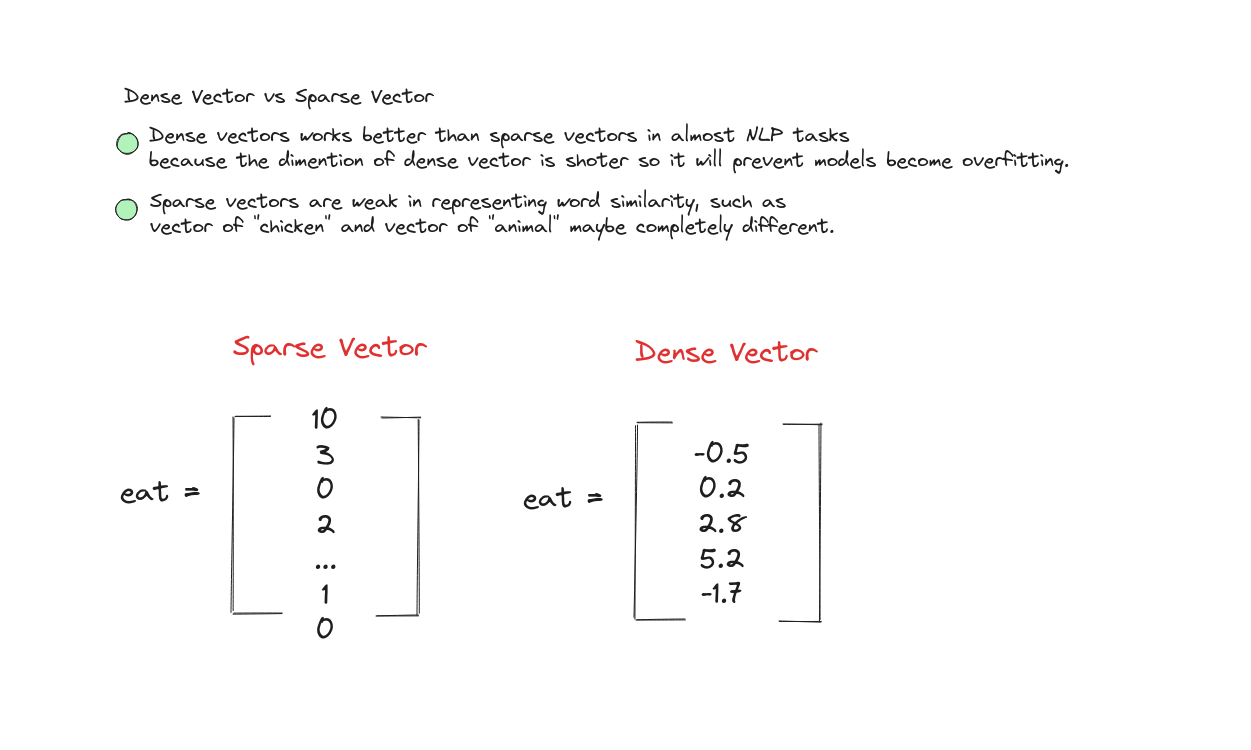
Word embedding là cách biểu diễn các từ dưới dạng vector dày đặc (dense vector) trong không gian liên tục, trong đó độ tương đồng giữa các từ được thể hiện qua khoảng cách giữa các vector. Thông thường, ta dùng cosine similarity để đo độ gần nhau về hướng giữa hai vector.
Word embedding thường được dùng để biểu diễn từ trước khi đưa vào các mô hình NLP.
Các vector này ngắn và dày đặc.
Word2Vec
Word2Vec là một loại embedding tĩnh, mỗi từ chỉ được biểu diễn bằng một vector cố định.
Điểm yếu của Word2Vec là không thể biểu diễn ngữ cảnh động, nên các kỹ thuật mới như ELMO, BERT và gần đây nhất là Attention ra đời để tạo embedding động (dynamic contextual embedding)—một từ có thể có nhiều vector khác nhau tùy ngữ cảnh. Phần này sẽ được nói kỹ hơn ở bài sau.
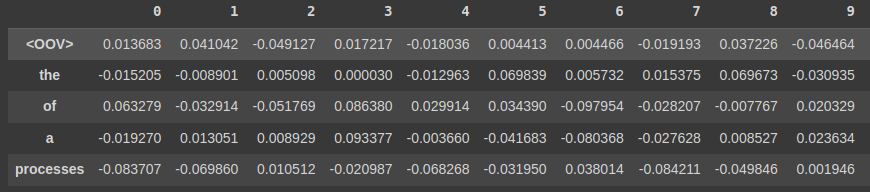
Cơ chế hoạt động của Word2Vec
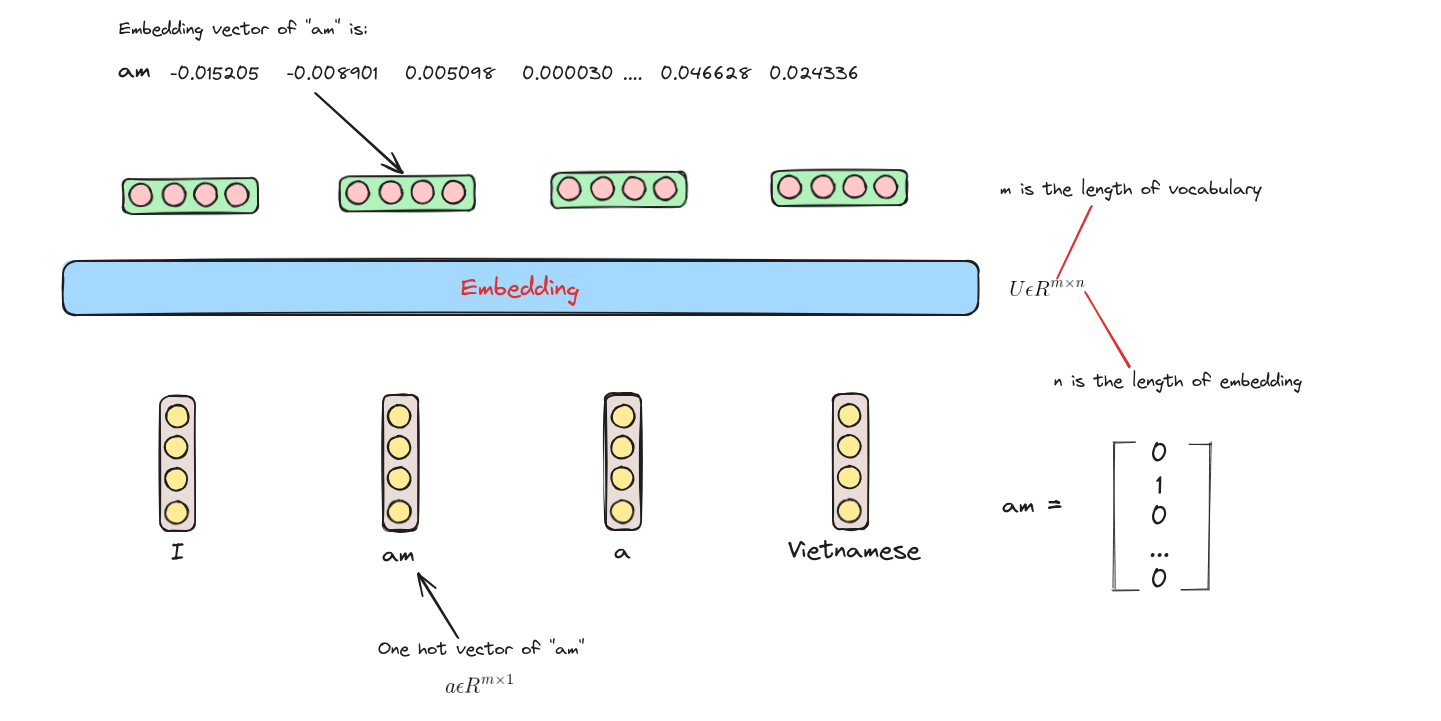
Mỗi từ đưa vào Word2Vec sẽ được chuyển thành một vector embedding để sử dụng cho các mô hình NLP.
Có hai cách xây dựng Word2Vec: Continuous Bag Of Words (CBOW) và Skip Gram.
Continuous Bag Of Words
CBOW là một loại mô hình word embedding trong NLP, dự đoán từ trung tâm dựa trên ngữ cảnh các từ xung quanh trong một cửa sổ cố định.
Cách hoạt động của CBOW
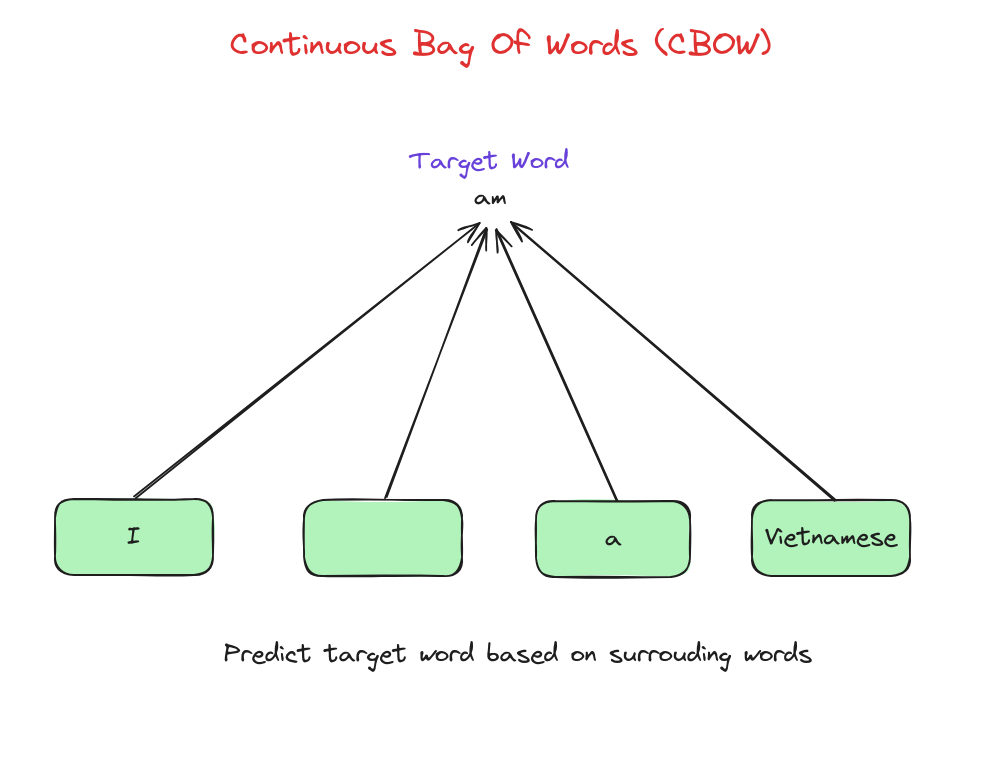
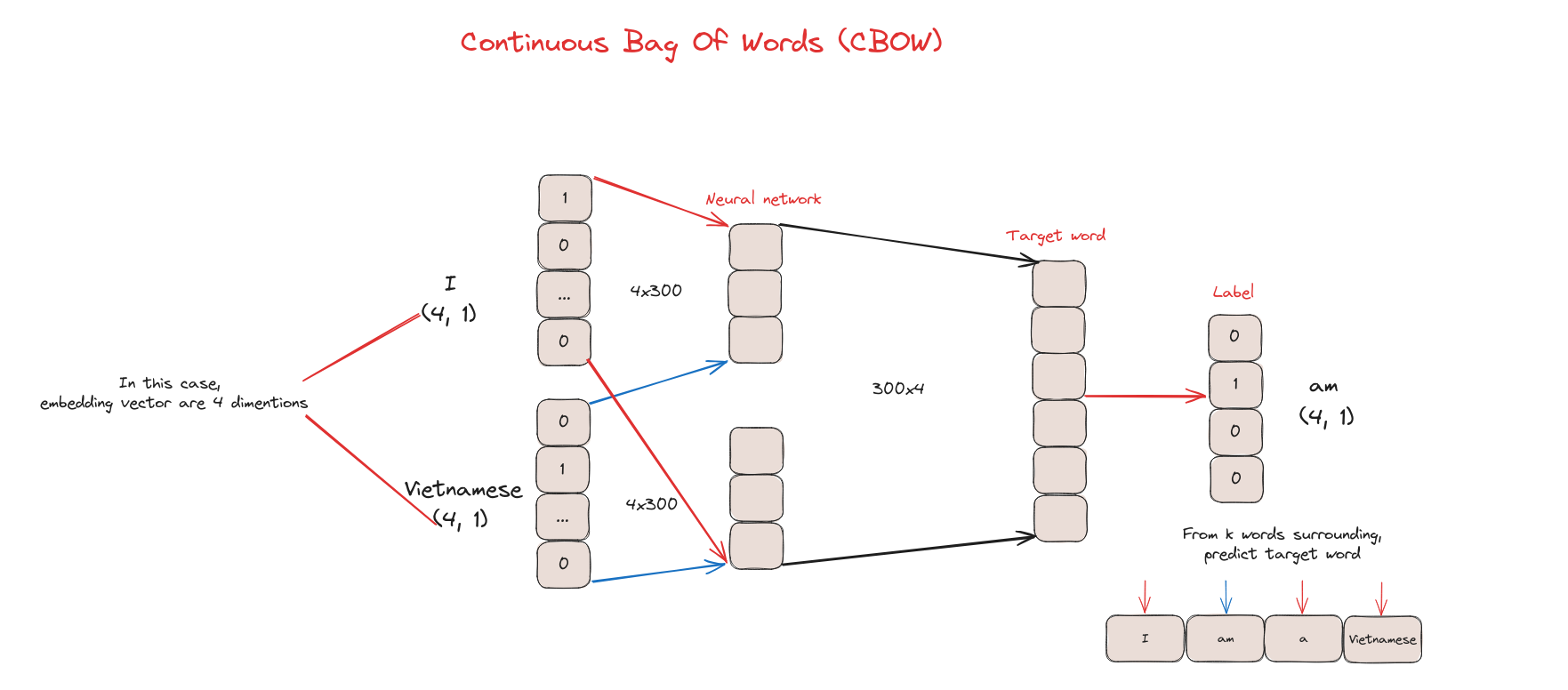
Các word embedding sinh ra từ CBOW có thể dùng cho nhiều tác vụ NLP như phân tích cảm xúc, mô hình ngôn ngữ, dịch máy…
Skip Gram
Skip-gram là một loại mô hình word embedding khác trong NLP. Khác với CBOW, Skip-gram dự đoán các từ ngữ cảnh dựa trên từ trung tâm.
Cách hoạt động của Skip Gram
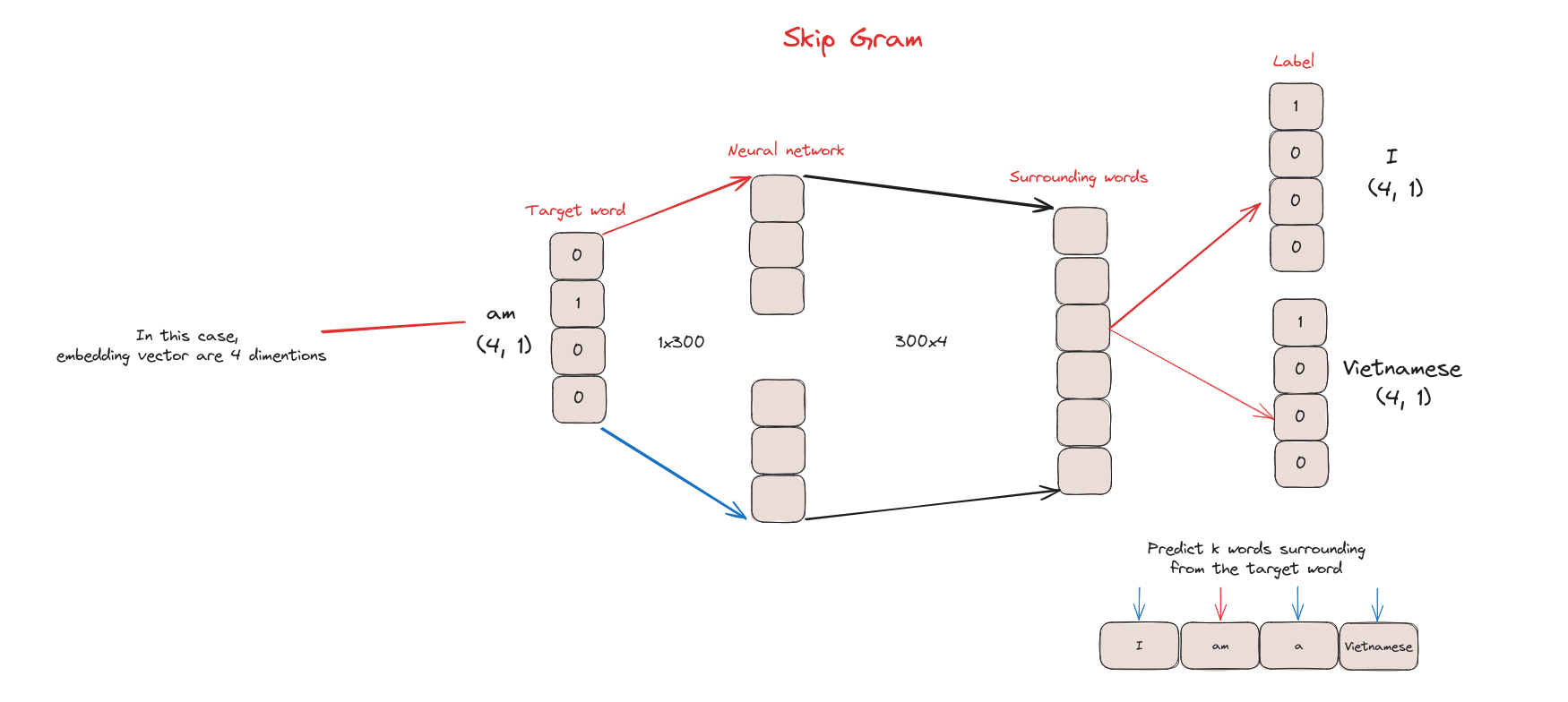
Skip Gram phù hợp khi muốn nắm bắt các mối quan hệ ngữ nghĩa tinh vi giữa các từ, hoặc quan tâm đến các từ hiếm và có tập dữ liệu lớn để huấn luyện. Nếu dữ liệu nhỏ hoặc muốn nắm ý nghĩa tổng thể, CBOW là lựa chọn tốt. Tương tự CBOW, Skip Gram cũng dùng cho các tác vụ như phân tích cảm xúc, mô hình ngôn ngữ, dịch máy…
Kết luận
Word Embedding là một kỹ thuật thiết yếu trong NLP giúp chuyển đổi từ thành vector liên tục, nắm bắt ý nghĩa và mối quan hệ giữa các từ, giúp mô hình hiểu ngữ cảnh, sắc thái ngữ nghĩa.
Tài liệu tham khảo
- IBM, “What are Word Embeddings?” www.ibm.com. https://www.ibm.com/topics/word-embeddings
- J. Alammar, “The Illustrated Word2vec,” jalammar.github.io, Mar. 27, 2019. https://jalammar.github.io/illustrated-word2vec/
- N. Barla, “The Ultimate Guide to Word Embeddings,” neptune.ai, Jul. 21, 2022. https://neptune.ai/blog/word-embeddings-guide